
Hello
Everyone! In this post, we will discuss about one of the advance topic in the
Spark and it is very confusing concept for the spark beginners and recently
people has started to ask questions based on this this topic and they want to
understand that what is your knowledge about how spark internally handles your spark SQL and how spark
internally handle your commands, whatever you have written as part of spark
code. So generally, they start with this
question like what is catalyst optimizer.
In this article, initially I will try to
understand you about Catalyst Optimizer through theory, later I will give you
demonstration about this concept.
Let us start …

What
happens if you are not a very experienced developer and your code will not be
optimized and it will not give you very good results but if you use dataframe
and dataset it gives you far better performance because SPARK internally takes
care of optimizing your code so optimizing your code and creating RDD execution
plan which will run fast.
Catalyst
optimizer is a component in spark, which is used for this optimization your
input can be coming from spark SQL, dataframe, dataset or some other things. When submit your code to spark it builds query
plan. It uses catalyst optimizer to
create optimized query plan and then optimized query plan is used to generate a
RDD code.

Now I am
going to discuss all the above phases in details. Let us discuss each phase one
by one.
1)
Unresolved Logical Plan:
In this phase, we submit Spark SQL query as an input. Let us suppose if
we are using dataframe or spark SQL and then we submit a query to spark in form
of unresolved logical plan.
2)
Logical Plan:
In this phase, firstly spark analyzes syntax, columns so on then it convert
the spark query in the form of a tree.
Spark operations we have defined on RDD it converts those chain SQL operations
into a tree and as you know first leaf nodes are regulated and then the parent
nodes.
3)
Optimized Logical Plan:
In this phase, spark gets SQL query in the form of tree after that spark
execute whole tree until it consumes the whole tree nodes. In this phase we start with the logical plan tree
so spark catalyst optimizer always talks in terms of trees so it applies
transformation on a tree and generates a new tree so in the end of multiple
transformations, we will get most optimized tree.
4)
Physical Plans:
In this phase, Spark check what kind of Joins or filter or aggregation operations
you have applied on data. After that
spark, evaluate the cost and used resources by all the operations.
5)
Select Physical Plan:
In this phase, Spark select only cost and resource effective operations
and the physical plan convert into RDD code then finally executed by Spark.
Let us
demonstrated each phase:
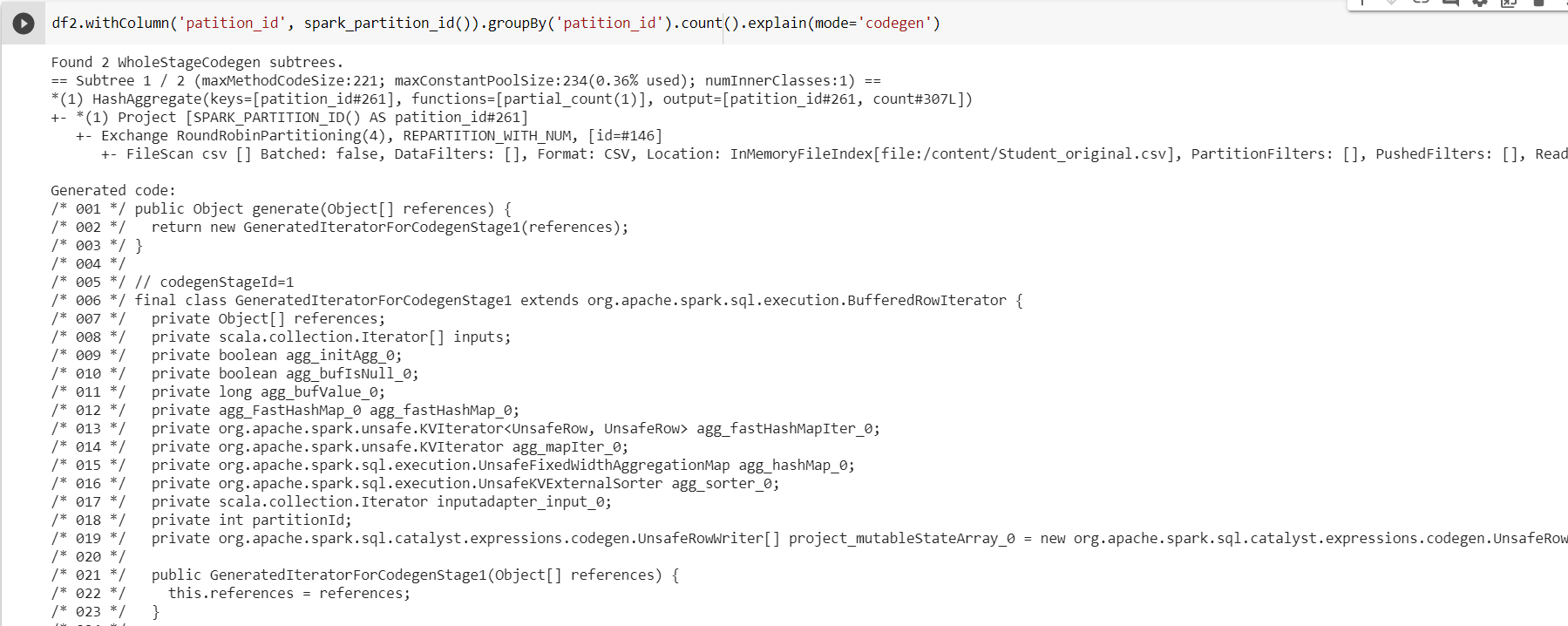
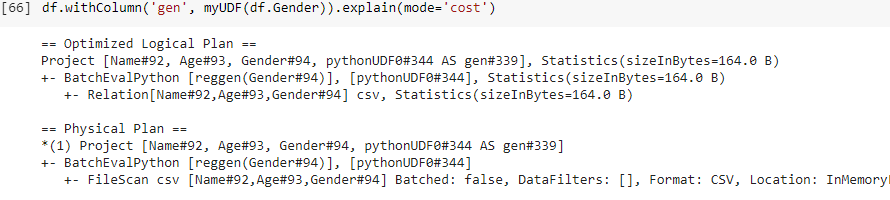
Explain ():
Specifies the expected output format of plans.
- Simple: Print only a physical plan.

- Extended: Print both logical and physical plans.

- codegen: Print a physical plan and generated codes if they are available.
- cost: Print a logical plan and statistics if they are available.
- formatted: Split explain output into two sections: a physical plan outline and node details.











Thanks revi kumar to explain spark in detailed manner.
ReplyDeleteCost based model it's not explained if possible pls explain in another post
Venu
Spark training in Hyderabad