Hello everyone! Today we are going to talk about
the components of Apache Spark. Spark contains several components and each
component has specific role in executing the Spark program.

First discuss about the
components and its responsibilities then we will deep dive into the workflow of
each component.
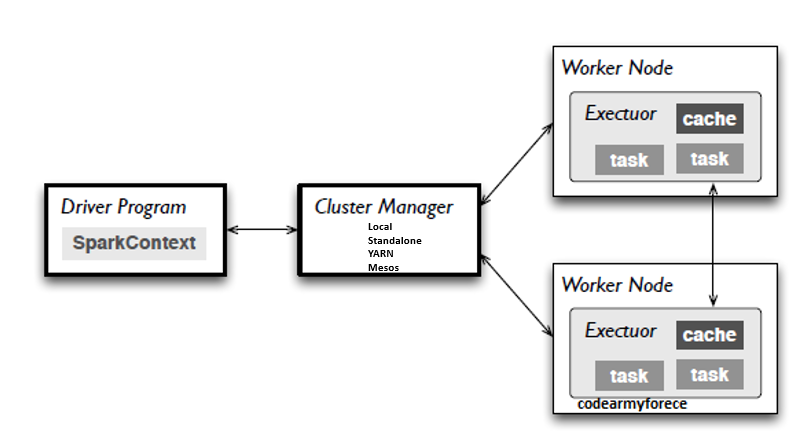
1) Worker:
It is one of the nodes which belong to Cluster and called slave. Workers have resources
(CPU+RAM) for executing the task.
2) Cluster
Manager: It have all information about the workers. It aware about the
available resource in workers. According to resource availability, decides to
distribute the particular to Workers. As we know that Spark have embedded resource
manager and we can use when we deploy the Spark on Standalone mode. Apart from
standalone mode, we can use customize resource manager like Local, YARN, Mesos
and Kubernetes.
3)
Driver: As the part of the Spark application
responsible for instantiating a SparkSession, the Spark driver has multiple
roles: it communicates with the cluster manager; it requests
resources (CPU, memory, etc.) from the cluster
manager for Spark’s executors (JVMs); and it transforms all the Spark
operations into DAG computations, schedules them, and distributes their
execution as tasks across the Spark executors. Once the resources are
allocated, it communicates directly with the executors.
Question: What is
difference between SparkSession and SparkContext?
Answer: Prior to Spark 2.0, entry point for the Spark applications
included the SparkContext, used for Spark apps; SQLContext, HiveContext,
StreamingContext. In Spark application, we have only one SparkContext.
The SparkSession
object introduced in Spark 2.0 combines all these objects into single
entry point that can be used for all Spark application. SparkSession object
contains all the runtime configuration properties set by the user such as the
master, application name, numbers of executors and more.
4)
Executors: A Spark executor runs on each
worker node in the cluster. The executors communicate with the driver program
and are responsible for executing tasks on the workers. In most deployments’
modes, only a single executor runs per node.
5)
Tasks: Small unit of job which is perform
by SparkContext.

SparkSession/SparkContext initiates on the client machine
and make the connection to master. Whenever we perform any Spark operation it
will communicate to master and logically directed acyclic graph called DAG. master
has all information about resources of workers. Now the driver talks to the
cluster manager and negotiates the resources. Cluster manager launches
executors in worker nodes on behalf of the driver. At this point, the driver
will send the tasks to the executors based on data placement. When executors
start, they register themselves with drivers. So, the driver will have a
complete view of executors that are executing the task. During the execution of
tasks, driver program will monitor the set of executors that runs. Driver node
also schedules future tasks based on data placement.










In Simple words, spark Context is entry point used to create rdd api.
ReplyDeleteWhereas
Spark session is unified context (sc,ssc,sqlcontext) etc ... Its used to create dataset.
Thanks to shar eu rknowledge Ravi Kumar.
Regards
Venu
bigdata training institute in Hyderabad
spark training in Hyderabad